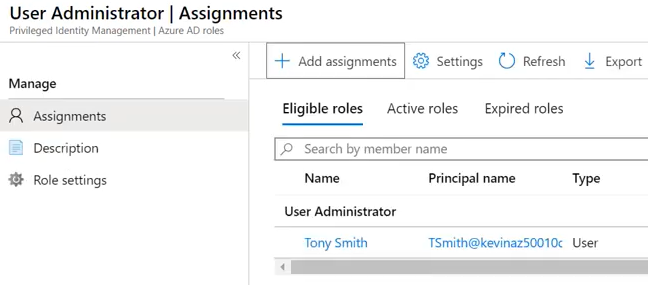
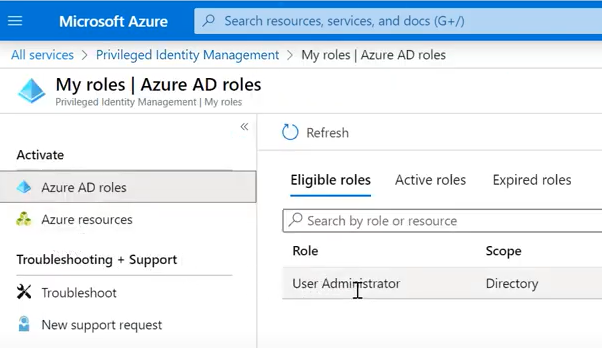
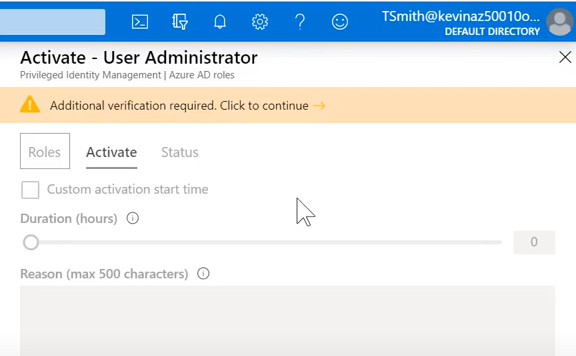
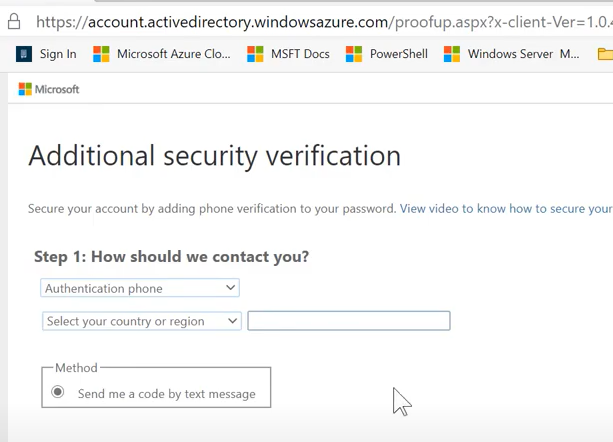
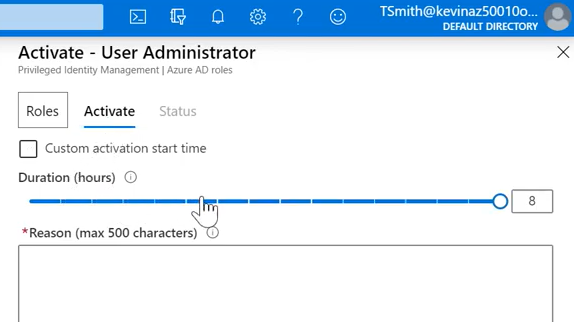
<예상 시나리오>
사내 백업솔루션이 떨궈놓은 백업 데이터에 대한 소산을 azure 클라우드 Blob저장소를 이용
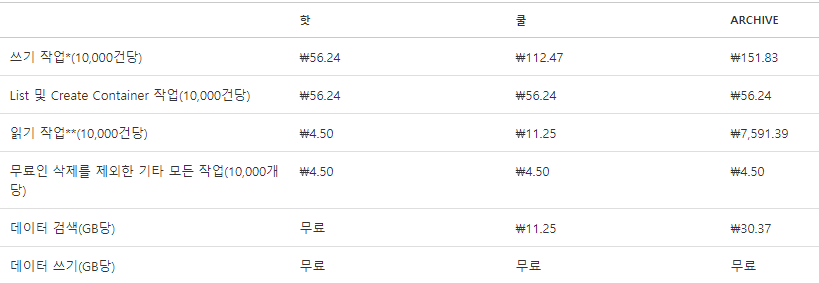
Hot타입에 대비하여 저렴한 Cool타입 Blob Storage 저장소에 업로드
업로드 자동화는 아래와 같이 azcopy 툴을 작업스케쥴러로 정기적으로 구동시키는 방안
파일을 복사하는 형태이기 때문에, 일일 변동 부분만 sync하는 것은 불가함,
-> 기존 Blob Storage 업로드한 데이터를 Archive 타입으로 변환처리하고,
새롭게 올린 데이터는 cool타입으로 유지시키는 방안 추천
AzCopy 유틸리티 및 SAS 토큰을 사용하여 스토리지 계정에 데이터를 백업하는 Windows 스케줄러 작업
출처: <https://techcommunity.microsoft.com/t5/azure-paas-blog/windows-scheduler-task-to-backup-your-data-to-storage-account/ba-p/1067860>
주의점 : SAS토큰 내용에 예: "%"와 "%%"
launch_process.ps1
<로컬 azcopy.exe 파일 경로> \azcopy.exe 동기화 " https://godhhhhhdkdutest.blob.core.windows.net/file?sp=rl&st=2021-08-13T15:11:52Z&se=2021-08-13T23: 11:52Z&sv=2020-08-04sr=csig=8dzwNkPZgHIjztGpT%2F2%2B3Jaxhqj6LsqG0m%2BrJeB%2BX%2FE%3D " " <대상 경로> "
작업 스케줄러를 구성하기 위해 XML 파일을 만드는 단계
이 XML 파일에서 Windows 작업 스케줄러의 구성을 정의합니다.
- 시작 경계 에서 작업을 트리거하는 데 필요한 시간을 제공할 수 있습니다.
- 일 간격 작업을 실행해야 하는 시간 간격을 정의합니다.
- 마지막으로 인수 에서 특정 시간에 실행해야 하는 파일 경로를 언급합니다.
작업.xml
<?xml 버전="1.0" 인코딩="UTF-16"?>
<작업 버전="1.2" xmlns=” http://schemas.microsoft.com/windows/2004/02/mit/task ">
<등록 정보 >
<Date>2021–08–14T00:37:46.1335413</Date>
<Author>SahayaGodson</Author>
<URI>\MAXERrecurrentDownload</URI>
</RegistrationInfo>
<Triggers>
<CalendarTrigger>
<StartBoundary>2021–08 –14T01:13:00</StartBoundary>
<Enabled>true</Enabled>
<ScheduleByDay>
<DaysInterval>1</DaysInterval>
</ScheduleByDay>
</CalendarTrigger>
</Triggers>
<Principals>
<Principal id=”저자”>
<UserId>S-1–12–1–1926020177–1169294588–4151075990–3368394568</UserId>
<LogonType>InteractiveToken</LogonType>
<RunLevel>HighestAvailable</RunLevel>
</Principal>
</Principals>
<Settings>
<MultipleInstancesPolicy>StopExisting</MultipleInstancesPolicy>
<DisallowStartIfOnBatteries>false</DisallowStartIfOnBatteries>
<StopiesIfGotrue> <StopIfGotrue >
<AllowHardTerminate>true</AllowHardTerminate>
<StartWhenAvailable>true</StartWhenAvailable>
<RunOnlyIfNetworkAvailable>false</RunOnlyIfNetworkAvailable>
<IdleSettings>
<StopOnIdleEnd>true</StopOnIdleEnd>
<RestartOnIdle>false</RestartOn/IdleSettings> <AllowStartOnDemand>true</AllowStartOnDemand> <Enabled>true</Enabled><Hidden>거짓</Hidden>
<RunOnlyIfIdle>거짓</RunOnlyIfIdle>
<WakeToRun>거짓</WakeToRun>
<ExecutionTimeLimit>PT72H</ExecutionTimeLimit>
<우선순위>7</Priority>
<RestartOnFailure>
<간격>PT1M</Interval >
<Count>3</Count>
</RestartOnFailure>
</Settings>
<Actions Context="Author">
<Exec>
<Command>powershell</Command>
<Arguments>-ExecutionPolicy ByPass -파일 replace_with_your_scrpit_path\launch_process.ps1< /인수></Exec></Action></Task>