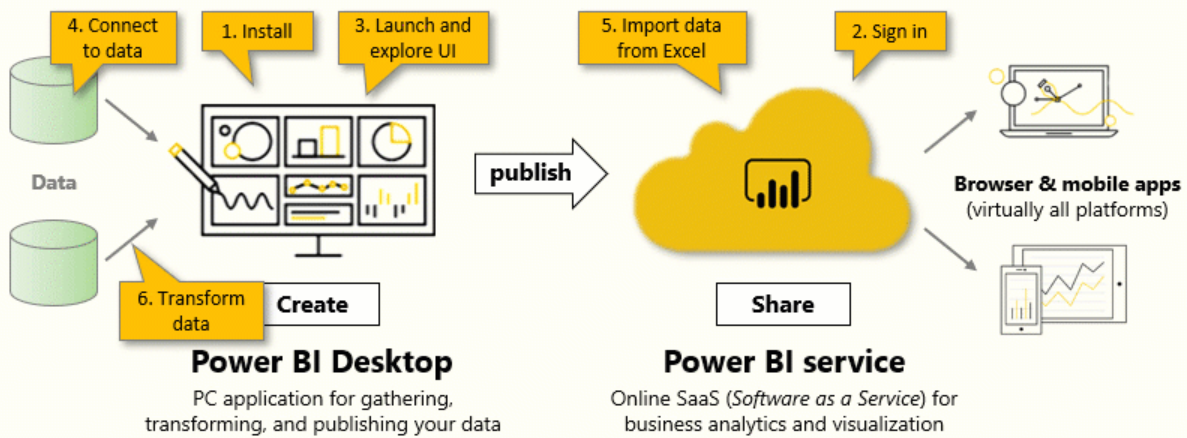
지식마이닝 서비스
장점
다른 AI서비스 Cognitive svc를 활용이 용이하다.
이미지처리, 자연어처리, 콘텐츠 추출등에 다른 서비스 활용
목적
대량의 데이터에서 신속하게 인사이트를 추출가능함.
- Azure Cognitive Search에서 인식 기술을 사용하는 방법 이해
- 인덱서가 JSON serialization을 포함하여 데이터 수집 단계를 자동화하는 방법 알아보기
- 지식 저장소의 용도 설명
- 검색 인덱스 빌드 및 쿼리
구조적, 반구조적, 비구조적 문서들에서 데이터를
효과적이고 빠르게 추출하는 검색솔루션을 만들기 위한
인프라와 도구 제공
오픈 소스 소프트웨어 라이브러리인 Apache Lucene을 기반
쿼리 및 Full text search 기능제공
JSON형식 모든 원본데이터 지원
Azure 스토리지 연계가능
자동완성, 자동제안 기능,
적중항목 강조기능 제공
인덱서
원본데이터의 JSON직렬화 후 검색엔진에 전달
변경검색을 지원? 바뀐것만???
검색인덱스로 JSON데이터를 Push
<데이터로드>
데이터원본에서 데이터를 가져올때 Pull
기본제공기술
자연어 처리 기술: 이러한 기술로 비구조적 텍스트는 인덱스에서 검색 및 필터링 가능한 필드로 매핑됩니다.
일부 사례:
- 핵심 구 추출: 미리 학습된 모델을 사용하여 용어 배치, 언어 규칙, 다른 용어에 대한 근접성 및 원본 데이터 내에서 용어가 비정상적인 정도에 따라 중요한 구를 검색합니다.
- 텍스트 번역 기술: 미리 학습된 모델을 사용하여 정규화 또는 지역화 사용 사례를 위해 입력 텍스트를 다양한 언어로 번역합니다.
이미지 처리 기술: 이미지 콘텐츠의 텍스트 표현을 만들어 Azure Cognitive Search의 쿼리 기능을 사용하여 검색할 수 있도록 합니다.
일부 사례:
- 이미지 분석 기술: 이미지 검색 알고리즘을 사용하여 이미지의 콘텐츠를 식별하고 텍스트 설명을 생성합니다.
- OCR(광학 문자 인식) 기술: 문서송장, 청구서, 재무 보고서, 문서 등과 함께 도로 표지판 및 제품 사진과 같은 이미지에서 인쇄되거나 필기된 텍스트를 추출할 수 있습니다.
인덱스 = 테이블
행 = 문서

문서의 각 필드에 대해
검색, 필터링, 정렬 등을 선택할 수 있음.
- 테이블 프로젝션은 쿼리 및 시각화를 위해 관계형 스키마에서 추출된 데이터를 구조화하는 데 사용됩니다.
- 개체 프로젝션은 각 데이터 엔터티를 나타내는 JSON 문서입니다.
- 파일 프로젝션은 추출된 이미지를 JPG 형식으로 저장하는 데 사용됩니다.
'기술(Azure 만...) > Azure빅데이터,분석' 카테고리의 다른 글
| Azure OpenAI가 생겼음 202303 (0) | 2023.03.16 |
|---|---|
| 시계열데이터 분석 (0) | 2023.02.27 |
| 데이터 마이닝 클러스터링(Clustering) (0) | 2022.09.29 |
| Azure Data Factory 다시 요약 (0) | 2022.04.29 |
| influxDB 정보 요약 (0) | 2022.03.16 |