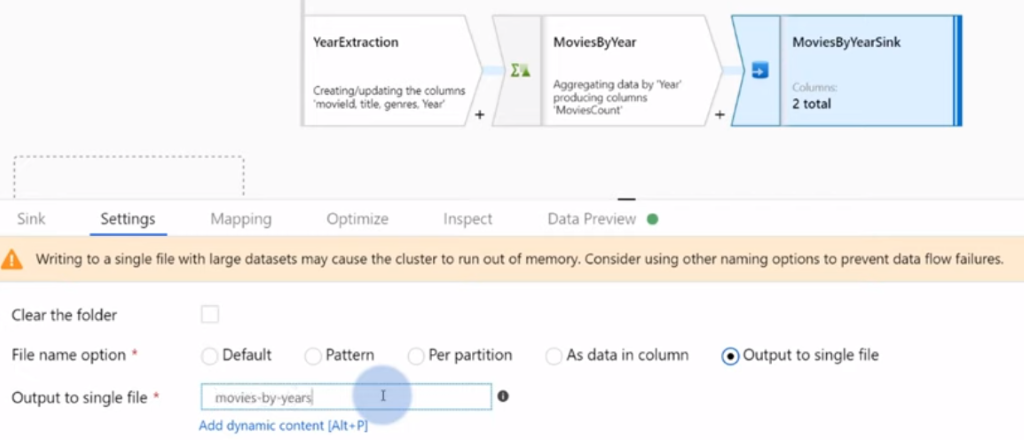
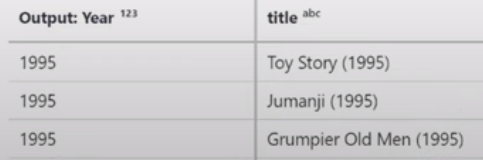
실제로 사용해봐야지 기억이 되지...
계속 봐도 기억안남
DW
- 조직 내 여러 데이터 원본에서 한곳으로 담을수 있는 곳
- 여러가지 형태의 원본데이터를 표준형식으로 변형하여 한곳에 담음(ADLS, SQL 등)
- ETL
- 복잡한 쿼리에 대한 답변을 제공하는 곳
- 분석/보고/OLAP 처러의 원본이 되는 곳
Online analytical processing
OLAP : DW의 데이터를 전략적인 정보로 변환시키는 시스템
- 주기적으로/ 실시간으로 데이터 저장이 되어야함
일괄처리/스트림처리
- 실시간 데이터 수집(스트리밍) -> 즉각적인 의사결정이 가능하도록
- 거의 limit 이 없는 사이즈
데이터원본 -> ADF(데이터통합서비스) -> DW(ADLS)-> AzureSnapse/Databricks/ -> Azure Analysis/ML -> PBI
판매량을 예측해서 적정생산량을 미리 결정하여,
사전 반영 한다,
원자재주문이나, 인력운영계획, 장비운영계획 등에 반영
|
ADF |
데이터통합서비스 N개의 데이터원본 ---- 파이프라이닝 구성-- 적재(ADLS 혹은 기타) 파이프라인의 지속적 실행 |
|
|
Azure Synapse Analytics |
마치 끊없이 생성되는 세포처럼 리밋없는 분석서비스라는 의미 제어노드 + 컴퓨팅노드풀
페타바이트 원본데이터도 가능 / 스케일링 기능이 있음. |
1.Snapse SQL
|
|
Azure Databricks |
Azure 에서 실행되는 Apache Spark(빅데이터처리엔진)환경
|
|
|
Analysis Services |
상관관계가 있는 여러 개 데이터원본을 연결, 결합, 필터링, 집계가 가능 데이터탐색 및 PBI로 시각화도 가능 테라바이트 데이터에 적합 표형식데이터, 신속한 대시보드 구성 가능 |
|
|
Azure HDinsight |
Spark뿐 아니라 Apache Kafka 및 Apache Hadoop 처리 모델도 제공
|
노드가 Azure SQL Database가 아닌 Spark 처리 엔진을 실행한다? |
데이터 레이크는 ‘원시 데이터’를 보관하지만 데이터 웨어하우스는 ‘구조화된 정보’를 보관합니다.
PolyBase
- SQL Server 2016 이상 버전(Windows만 해당)
- 분석 플랫폼 시스템(이전의 병렬 데이터 웨어하우스)
- Azure Synapse Analytics
SQL서버에 추가하면 여러가지 데이터를 TSQL 하여 가져올 수 있음.(조인 가능)
SQL에 해당 DB가 생성+외부테이블생성, 거기에 저장함
외부커넥터제공
SQL Server
쿼리가능 저장소
Blob Storage, Hadoop, SQL
설치방법



'기술(Azure 만...) > Azure빅데이터,분석' 카테고리의 다른 글
| ADF 또 요약 (0) | 2021.11.14 |
|---|---|
| KepserverEX - Iot Edge - Iot Hub (0) | 2021.07.16 |
| 데이터분석 기초 (0) | 2020.09.09 |
| ADF data mapping dataflow (0) | 2020.04.19 |
| ADF Parametrization 매개변수화 (0) | 2020.04.19 |