Artificial Intelligence for Beginners
https://github.com/microsoft/AI-For-Beginners
GitHub - microsoft/AI-For-Beginners: 12 Weeks, 24 Lessons, AI for All!
12 Weeks, 24 Lessons, AI for All! Contribute to microsoft/AI-For-Beginners development by creating an account on GitHub.
github.com
Artificial Intelligence for Beginners
'Tech(테크) > AI관련' 카테고리의 다른 글
| 텍스트임베딩과 벡터검색 (0) | 2023.10.20 |
|---|---|
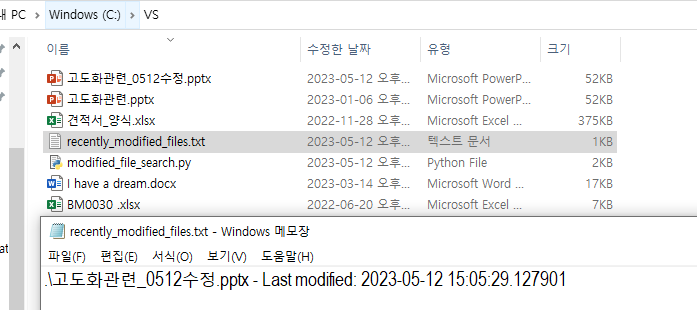
| chatGPT에게 파이썬 프로그램 하나요청 해봄 (0) | 2023.05.12 |
| chatGPT 좀 더 깊게 (0) | 2023.03.28 |
| chatGPT 학습데이터셋의 신뢰도 측면? (0) | 2023.03.19 |
| chatGPT 다국어 측면 질문 (1) | 2023.03.19 |