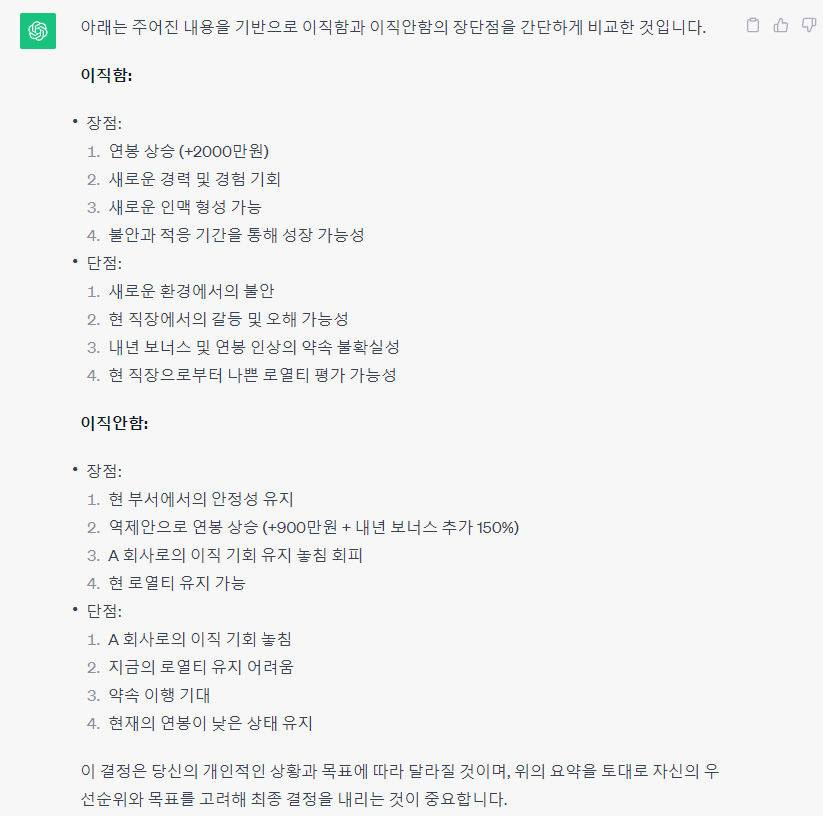
이직 시 기존회사에서 역제안을 받는 경우
이직회사는 연봉 +2천
기존회사는 연봉 + 천만원 + 보너스
아래 2가지 경우에 대한 장단점 및 코멘트를 나열해보자
| 그냥 이직 | 기존 회사 남는다 |
| 보통 역제안이 더 높은 연봉을 불러줘야됨. 구두약속은 믿을 수 없음. 제안을 한 본부장이 내년에 없을 수도 있음 |
사직의사를 밝히는 순간 회사에 대한 로열티평가는 최하로 바뀜 한번 그러한 이력이 있다면, 언제든지 나갈 수 있는 사람으로 입에 오르내림. 수락 시 관계가 뒤바뀜. 칼자루는 상사가 쥐게됨. |
| 천만원 차이 인데 간다 기본급이 오르면 퇴직금도 오른다 1년 버티고 이직 시, +2천연봉으로 시작한다. 기회가 왔을 때 옮긴다. |
새회사에서의 새로운 인맥형성 매우 힘들다, 새로운 회사에 이상한 사람들이 있을 가능성 (기존 지인이 있는 회사라면 상태를 잘 알고 있으니 상관없음) |
| 지금은 계단을 오를 때 현실에 안주하면 뒤떨어짐. 보너스는 개구라임. |
구두보다는 기존연봉 + 천만원 연봉계약서를 들고 얘기하는 것이 좋을듯. |
질문본문내용 추가로 댓글까지 긁어서, GPT에게 요약요청
'Tech(테크) > 취업준비,회사생활,채용등' 카테고리의 다른 글
| 데이터 엔지니어 채용, 입사 관련 (0) | 2023.09.02 |
|---|




